
Oct 20, 2020 Max Uppenkamp
ShareData quality is an innocuous term. Upon first encounter, the association is usually big tables filled with numbers, some of which erroneous, math, and complex statistics. The consequences, however, can be very real.
In my previous article “Data Cleaning: Pitfalls and solutions” I shed some light on some of the shapes data quality issues can take. I also talked about a few approaches towards improving data quality and shared some insight on the business impact of inadequate data quality. Today, I would like to approach the topic from a more tangible perspective.
To that end we will look at two disasters on different scales, find the data quality issue embedded in the chain of events, and attempt to learn from the outcome. Finally, we will extrapolate from the lessons learned and form a general approach to weighing data quality risks and strategies.
Case One: Challenger Explosion, 1986
In 1986, NASA launched the space shuttle Challenger, manned by seven astronauts. Just moments after the take-off the shuttle exploded, resulting the entire crew’s demise. It is widely agreed that the cause of the explosion was an O-ring that failed after being subjected to low temperatures and high pressure during the launch. As a result, flammable gases escaped their containers and ignited, causing the disaster.
If we look beyond the technical aspect, we find that the O-ring issue was known well in advance and could have been prevented with better data-keeping and decision-making procedures. In fact, concerns about the O-ring were raised as early as 9 months prior, and even the manufacturer objected to the launch, only to reconsider after hours of debate. Unfortunately, NASA management operated on inconsistent and incomplete data.
The component in question was documented in multiple database system, each pertaining to a different aspect of manufacturing and planning. In some of these systems the O-ring was correctly labeled as “critical”, while in others it was classified as “redundant”, meaning its failure would be backed up by other equipment. The redundancy of multiple systems also meant that information would often not be identically maintained and would therefore diverge. This led to one engineer closing the O-ring investigation as resolved based on the information of just one database, thereby ending all further technical inquiry.
The existence of multiple systems also led to the usage of incomplete information. Even though the necessary data to analyze the effect of temperature on the O-ring was available, it was fragmented in the different databases, and only part of it was used in the regression analyses done by both NASA and the manufacturer
Of course, the Challenger Disaster cannot be attributed solely to data quality issues. Failure of communication happened in multiple instances and office politics contributed to the insufficient distribution of information.
Lesson learned
This story shows multiple failures in storing and applying information. Firstly, maintaining redundant systems without proper synchronization procedures leads to inconsistent knowledge, and therefore to inconsistent decision-making. A normalized and well-maintained database would have allowed for the simplification and improvement of operational processes.
Secondly, both engineers and management unknowingly relied on incomplete information. While this is as much a problem of procedure as it is one of data quality, it shows that data accessibility is an essential component of data strategy.
Lastly, this story shows that even great care for technical detail a great efforts in planning can be rendered useless by lack of a comprehensive data strategy.
Case Two: But Google Maps said…
In 2016 a Texas-native woman received a call from her neighbors that her house had been destroyed by a demolition company. Upon investigation it turned out that the company had executed their assignment at was what they thought the correct location. In reality the correct address was a different, desolate home one block over.
This mistake obviously came down to a data problem in form of an incorrect address listing. The faulty data, however, was not their own. The demolition crew had entered the given address into Google Maps, and received the wrong location.
As the image below shows, Google lists the same location for the two addresses to this day.
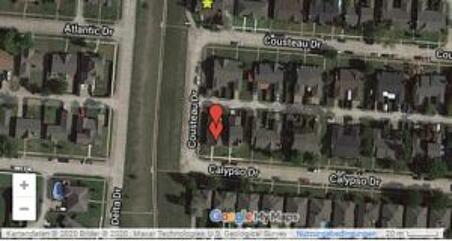
Lessons Learned
Cases like this one are reported regularly across the world. Sometimes it is an unfortunately mistaken demolition job, sometimes drivers, blindly following their GPS, placing their vehicles into rivers, lakes or people’s homes.
These superficially entertaining anecdotes highlight an underlying disconnect in stakes and data quality. To a company like Google, lapses in the accuracy of their maps carry very little consequence and are highly impractical to correct exhaustively.
Issues arise, when this data is relied upon in a context where the stakes are much higher, be it the demolition of a home, or placing one’s life into the hands of a GPS system.
As for the lessons learned: When picking a source of data, consider the implications of faulty information, and if no satisfying source of data is available, make sure to verify before taking action. In this case, checking the street sign would have sufficed.
Note: When relying on third party data, it is necessary to evaluate whether the data provider is as invested in its correctness as the user is.
Conclusion: Weighing criticality and prioritizing accordingly
We looked at two cases where insufficient data quality led or contributed to grave consequences. While similar in outcome, they differ in the way that NASA collected and maintained their own data, and the demolition company relied upon external data. Obviously in most instances of data-driven decision-making, the stakes are not nearly as high, but the concept holds. Businesses are often overwhelmed when it comes to assessing the quality of the data they might have amassed over decades.
The often-taken approach of posing the question “Which data is most important?” is, in my opinion, flawed. It should much rather be phrased as “Where can faulty data cause the most damage?”. If potential damage is not a factor, prioritization should be driven by potential benefit, be it economically or otherwise.
This article was originally published on the INFORM DataLab Blog.
About our Expert
Max Uppenkamp
Max Uppenkamp has been a Data Scientist at INFORM since 2019. After previously working in Natural Language Processing and Text Mining, he is now engaged in the machine-learning-supported optimization of processes.
In addition to accompanying customer projects, he translates the knowledge gained into practice-oriented products and solutions.
